
Come si calcola l’Analisi Fattoriale Esplorativa in Psicologia
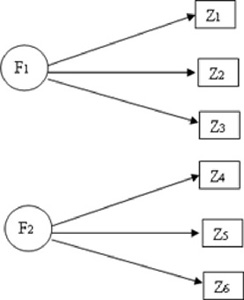
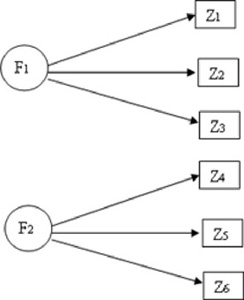 L’analisi fattoriale esplorativa riconduce una serie di M variabili manifeste, tra loro correlate, a un numero inferiore di H variabili latenti, dette fattori.
L’analisi fattoriale esplorativa riconduce una serie di M variabili manifeste, tra loro correlate, a un numero inferiore di H variabili latenti, dette fattori.
Le correlazioni fra variabili manifeste sono spurie, quindi scompaiono dopo aver tenuto conto delle variabili latenti.
L’input minimo della tecnica è la matrice delle correlazioni R di forma MXM, che devono essere calcolate ad un livello di scala cardinale.
Un altro utilizzo di questa scala è testare l’unidimensionalità della scala. Il punto di partenza è sempre la matrice delle correlazioni (R di forma MXM), il punto di arrivo è una matrice MXH (la soluzione della tecnica).
Per passare dalla matrice R di forma MXM alla matrice MXH si utilizza un metodo di estrazione dei fattori (la massima verosimiglianza) si stimano le correlazioni (saturazioni) che legano ciascuna variabile manifesta a ciascuno dei fattori latenti ( che sono responsabili di aver creato quelle correlazioni tra variabili manifeste contenute nella matrice R di partenza e che il ricercatore ha il dubbio siano spurie).
Procedimento dell’Analisi Fattoriale Esplorativa:
Il ricercatore per prima cosa decide il numero di fattori da estrarre: ne estrarrà uno e valuterà la bontà dell’ipotesi che ci sia un solo fattore all’origine delle correlazioni manifeste. Poi ne estrarrà due e farà la stessa cosa, poi tre e così via.
Il numero massimo di fattori da estrarre può essere definito dal criterio della curvatura dello scree plot, dove in ascissa si trova il numero di fattori che è possibile estrarre, e in ordinata gli autovalori che esprimono la varianza spiegata di ciascun fattore. Di solito si sceglie di estrarre il numero di fattori che stanno prima del gomito della curva.
Siamo giunti a una buona soluzione quando riusciamo a riprodurre la matrice delle correlazioni R facendo pochi errori.
I metodi per valutare la bontà di un modello fattoriale (1,2,3,… variabili latenti) sono:
-
IL REPR:
Per prima cosa si utilizza il METODO DELLA MASSIMA VEROSIMIGLIANZA, che stima quelle saturazioni fra ciascun fattore e ciascuna variabile manifesta che presentano la massima probabilità di riprodurre le correlazioni osservate, dato un certo modello fattoriale.
Si produce quindi una matrice A delle saturazioni che, moltiplicata per la sua trasposta A’ dà luogo a una matrice delle correlazioni (R^): queste correlazioni non sono mai identiche a quelle osservate, ma sono quelle riprodotte ipotizzando che al di sotto delle correlazioni manifeste esistano tot fattori.
R^=AA’
Se il modello fattoriale è corretto allora le correlazioni saranno molto simili a quelle osservate:
ecco perché si calcola il REPR, che è proprio un Indice della vicinanza tra le matrici delle correlazioni manifeste e quelle riprodotte. Esso indica la percentuale delle celle in cui gli scostamenti tra le due matrici di correlazione sono maggiori di 0,05. Accettiamo di regola percentuali inferiori al 20 percento. Più piccolo è il REPR più simili sono le due matrici; qualora il REPR non fosse soddisfacente è opportuno aumentare il numero di fattori estratti.
Una volta decisa l’unidimensionalità della soluzione ( da H=1 a H=M-1) e valutata la sua qualità, si passa alla fase di etichettamento dei fattori estratti.
Per farlo si ispeziona la matrice A dei FACTOR LOADING (coordinate degli item) e si individuano gli item che correlano molto con un fattore e poco con gli altri.
La soluzione canonica, che è quella che l’algoritmo calcola per prima, può risultare poco nitida.
Per aiutarci possiamo usare il secondo criterio di valutazione della bontà del modello fattoriale:
-
Rotazione della Matrice A
Un altro criterio, accanto al REPR che è soprattutto statistico, ne esiste un secondo di natura semantica, riguarda l’etichettamento, il nome da attribuire a ciascun fattore.
La matrice A, creata grazie al metodo della massima verosimiglianza, è per sua natura poco chiara e leggibile, cioè si fa fatica a capire per ogni variabile manifesta con quale fattore correli di più, in quanto le saturazioni di ogni variabile manifesta tendono ad essere piuttosto alte e simili fra loro.
Allora per rendere più interpretabile la matrice A, si procede alla sua rotazione (procedimento che non modifica le correlazioni riprodotte, ma solo le saturazioni), cioè si ruotano le posizioni degli assi che rappresentano i fattori, in modo tale che goni variabile correli molto con un fattore e poco con gli altri.
Conviene prima applicare la ROTAZIONE OBLIQUA, che stima le correlazioni fra i fattori; se questa correlazione è piccola si passa alla ROTAZIONE ORTOGONALE, che considera i fattori indipendenti fra loro.
Effettuata la rotazione, la matrice A è molto leggibile, quindi è possibile per ogni fattore individuare i suoi MARKER, ovvero quelle variabili manifeste che hanno con lui un’elevata saturazione e bassissima con gli altri.
Questi marker guideranno il ricercatore nel trovare un nome, un’interpretazione semantica, al fattore, in quanto sono da considerarsi i suoi indicatori empirici migliori.
Infine, quando oltre alla matrice MXM si ha a disposizione anche la matrice CXV, è possibile stimare la posizione dei soggetti lungo un continuum latente individuato da ciascuno dei fattori estratti.
In questo modo, alla matrice CXV vengono aggiunte tante colonne quanti sono i fattori estratti che contengono i punteggi di ciascun individuo, relativi a ciascun fattore (FACTOR SCORES).
I punteggi fattoriali sono utili quando si vogliono selezionare i soggetti in base ai punteggi ottenuti sulle diverse dimensioni di un test. Inoltre è possibile studiare le relazioni fra variabili latenti e le variabili contenute nella matrice CXV.
Il punteggio standardizzato (distribuzione standard, cioè media=0 e varianza=1) ottenuto da un soggetto in una variabile può essere espresso come la somma ponderata (attribuire ai diversi addendi un diverso peso) del punteggio ottenuto dallo stesso soggetto:
- Nei fattori comuni, che riflettono la variabilità che ogni variabile condivide con le altre variabili in analisi.
- Nel fattore unico, che riflette ciò che le variabili non condividono.
Zik=Fi1ak1+Fi2ak2+…+Fimakm+Uik
Dove:
Zik= punteggio standardizzato per la persona i nella variabile k
Fi1, Fim= punteggi standardizzati per la persona i nei fattori comuni (1,2,…,m)
ak1,akm= saturazione fattoriale (factor loading) della variabile k nei fattori comuni ( 1,2,…,m), ovvero il coeficente che misura la relazione fra la variabile osservata e il campione.
Uik= punteggio standardizzato per la persona i nel fattore unico associato alla variabile k
R=R^+D
Dove:
R=matrice MXM
D= errore
R^=matrice delle correlazioni tra le variabili riprodotta tramite le saturazioni fattoriali
La riproduzione della matrice delle correlazioni R avviene attraverso la costruzione di una matrice MXH che contiene le relazioni tra le variabili osservate e i fattori latenti e rappresenta la soluzione della tecnica.
Questo è possibile applicando l’equazione fondamentale dell’analisi fattoriale:
R=R^+D=AA’+U*2
Dove:
A=matrice di forma MXH
A’=trasposta della matrice A
U*2= termine residuale che tiene conto dell’unicità delle variabili
Che stabilisce che la matrice delle correlazioni manifeste può essere riprodotta tramite gli elementi contenuti nella matrice A di forma MXH che esprime le associazioni delle variabili osservate con i fattori latenti.
Assunti di base:
-
I fattori unici devono essere interpretati come errori casuali e dunque no sono correlati né fra loro né con i fattori comuni
-
Le M variabili manifeste sono standardizzate (distribuzione standard, cioè media=0 e varianza=1), il che rende le relative covarianze identiche alle correlazioni
-
Le H variabili latenti sono standardizzate
- I fattori comuni possono essere sia correlati fra loro, sia ortogonali (indipendenti). Cov(Fi;Fj) può essere anche diversa da 0.
Leggi tutti gli articoli di Psicometria
Hai bisogno di Ripetizioni di Psicometria? Clicca qui
Scrivi a Igor Vitale